
LLMs, simply explained: how your AI helper thinks
If you’ve used ChatGPT or another chatbot and wondered “What’s going on under the hood?”, here’s a gentle tour—no math, just the big ideas.
LLMs, simply explained: how your AI helper thinks
If you’ve used ChatGPT or another chatbot and wondered “What’s going on under the hood?”, here’s a gentle tour—no math, just the big ideas.
What is an LLM?
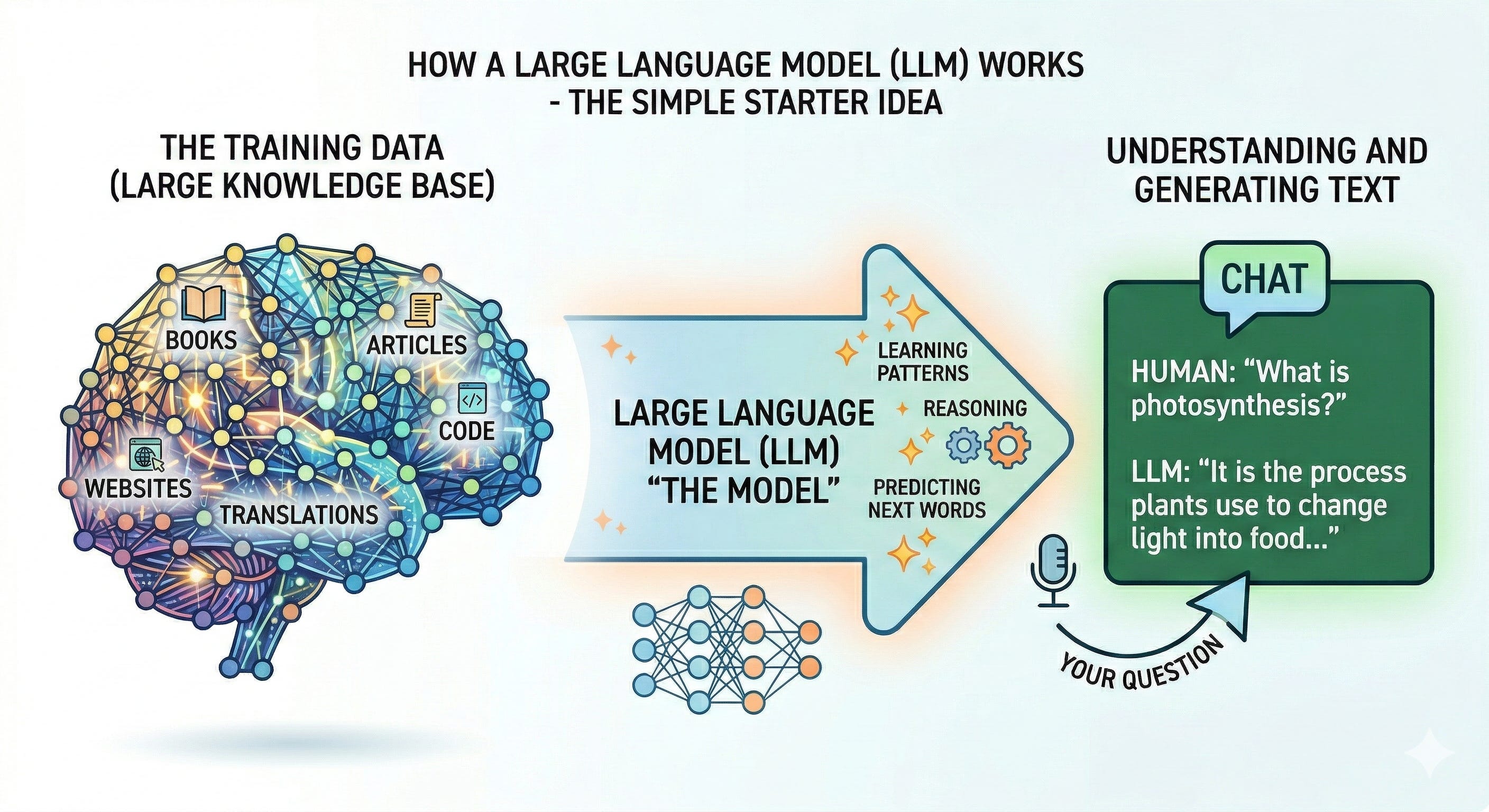
A Large Language Model (LLM) is a computer program trained to predict the next piece of text. Think of it as supercharged autocomplete. Give it some words, and it guesses what comes next—one small chunk at a time—until a full answer appears.
What does it learn from?
Lots of text. Books, articles, websites, code, conversations—public or licensed data gathered to teach the model general patterns of language.
It doesn’t memorize everything verbatim. Instead, it compresses patterns into billions of tiny dials called parameters (the model’s “memory of patterns”).
How does training work?
Imagine showing the model a sentence with one word hidden and asking it to guess the missing word. If it’s wrong, the system nudges those dials a tiny bit. Repeat this trillions of times, and the model becomes very good at guessing.
Over time it learns grammar, facts that appear frequently, writing styles, and how concepts relate.
What happens when you ask a question?
You type a prompt.
The text is broken into tokens—small pieces like words or word fragments.
The model looks at all previous tokens and predicts the most likely next token, then the next, and so on, forming a response.
It uses “attention,” a kind of spotlight that highlights the most relevant parts of your prompt and its own draft as it writes, helping it stay on topic.
Why does wording matter?
The model doesn’t “know” your intent; it follows patterns. Clear instructions narrow down what “next token” makes sense. That’s why good prompts help so much.
What are “weights,” “layers,” and “neurons”?
Layers: stacks of processing steps that refine the model’s understanding at each pass.
Neurons: tiny calculators inside layers that detect features (tone, topic shifts, code structure).
Weights: the dial settings learned during training that determine how strongly neurons respond.
Why do LLMs sometimes get things wrong?
They predict plausible text, not truth by default. If training data was thin, outdated, or mixed, the model may produce confident but incorrect answers (this is called a hallucination).
They don’t browse the web automatically unless connected to a tool; even then, they need to cite and reason carefully.
How can you get better answers?
Be specific: “Summarize this 800-word article in 3 bullets for a 10-year-old” beats “Summarize this.”
Give context: paste key details or constraints (audience, format, length).
Ask for reasoning: “Show steps” or “list assumptions” nudges the model to explain.
Set boundaries: “Use only information in the quote below” reduces made-up details.
What are LLMs great at?
Drafting text, rewriting for tone, summarizing, brainstorming, basic coding help, turning structureless notes into tidy formats.
Where are the limits?
Factual reliability without sources, long-term planning across many steps, nuanced real‑world judgment, and tasks needing fresh data unless tools are enabled.
Privacy: anything you share could be used to generate an answer. Avoid pasting sensitive data unless you’re using enterprise features designed for confidentiality.
A quick mental model
Autocomplete with a library card: it predicts text like autocomplete, but with a mental “index” of patterns learned from a vast library.
Spotlight attention: it continually asks “which parts matter right now?” to stay coherent.
Guardrails and tools: safety filters, web browsing, calculators, or code runners extend what it can do and help keep it on track.
The takeaway An LLM doesn’t think like a person; it recognizes and continues patterns in language at massive scale. With clear prompts and a bit of structure, you can harness that pattern power for everyday tasks—while staying mindful of its limits.