
AI will be wrong today. The question is what happens when it is.
That’s the real foundation of AI: not perfection, but managing the cost of being wrong under uncertainty. Every model is a bet.
AI will be wrong today. The question is what happens when it is.
That’s the real foundation of AI: not perfection, but managing the cost of being wrong under uncertainty. Every model is a bet. It weighs evidence, picks an action, and absorbs the consequences. The craft is deciding which mistakes you can afford—and which you can’t.
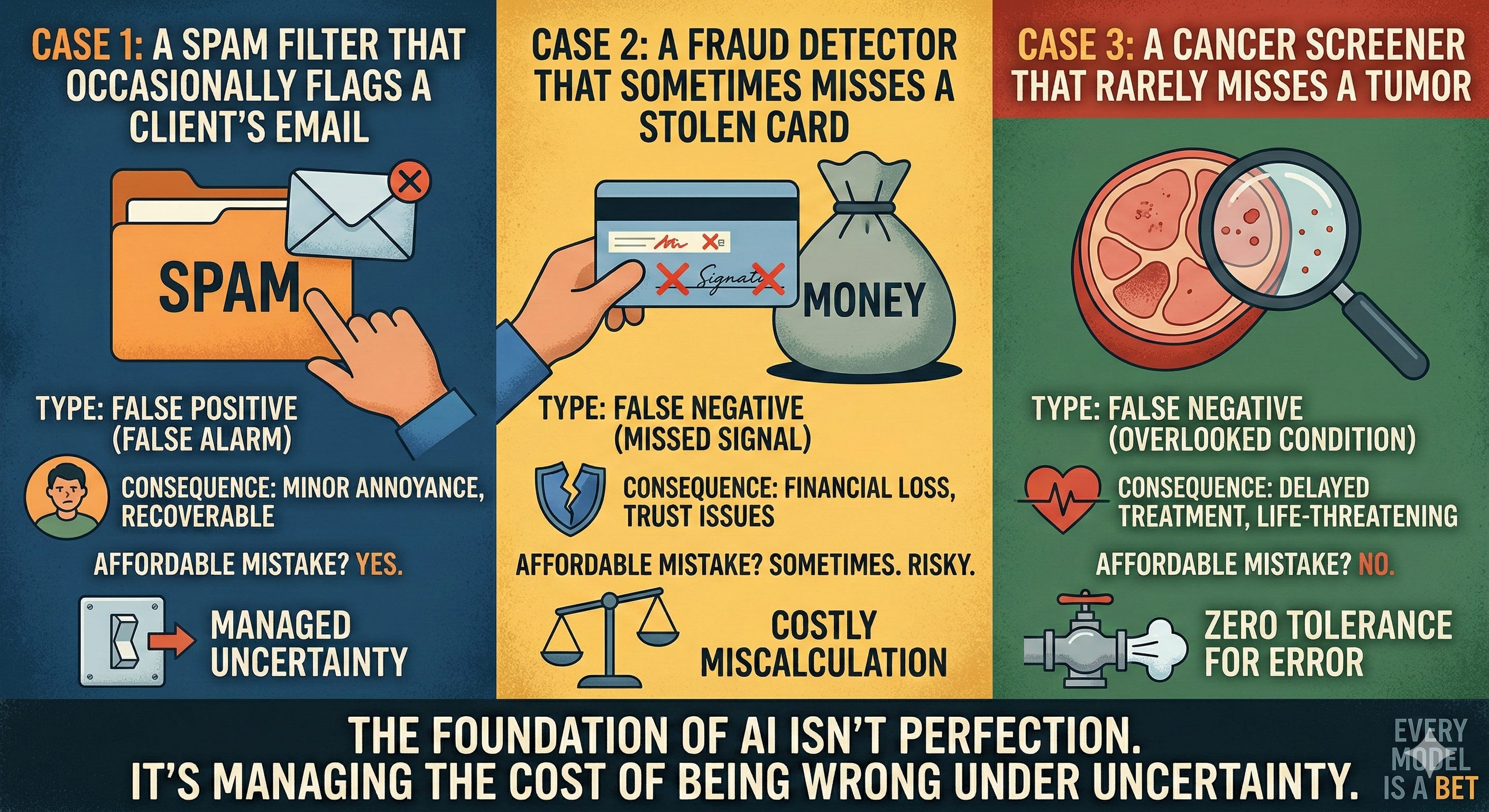
Think of three systems with the same “accuracy”:
A spam filter that occasionally flags a client’s email
A fraud detector that sometimes misses a stolen card
A cancer screener that rarely misses a tumor
Identical accuracy can be catastrophic in one case and trivial in another. Why? Because the costs of false positives and false negatives are wildly different. AI’s basis is to turn those asymmetries into math and policy: define loss, choose thresholds, and design fallbacks that minimize expected harm.
How AI actually encodes “cost of wrong”
Loss functions: We teach models what hurts. Weighted losses punish costly errors more, nudging the model to be “less wrong” where it matters.
Thresholds as policy knobs: The same model can be cautious or aggressive based on decision thresholds. Tune them to your stakes, not to a leaderboard metric.
Calibration: Confidence should mean something. Well-calibrated models know when to be unsure—and when to defer.
Selective prediction (the right to abstain): The safest answer is sometimes “I don’t know.” Deferrals to a human save you from expensive mistakes.
Cost-aligned metrics: Precision, recall, ROC-AUC are proxies. What you really want is expected cost/utility, decision curves, or cost-weighted error rates.
Make it concrete with a simple shift: In a hospital, missing a disease (false negative) is far worse than a false alarm—so you favor recall and accept more follow-ups. In content moderation, overblocking (false positive) might chill speech—so you favor precision, add appeals, and review edge cases. Same model family, different economics of error.
A playbook to manage the cost of being wrong
Map decisions and stakes
What action will the model trigger? Who’s affected? What can go wrong? List failure modes, including “unknown unknowns.”
2. Put prices on errors
Assign relative costs to false positives/negatives, slow vs fast decisions, automating vs deferring. Imperfect prices beat none.
3. Encode costs in training and evaluation
Use cost-sensitive losses, stratified objectives per segment, and cost-weighted metrics—not just accuracy.
4. Design for uncertainty
Calibrate probabilities, support abstain/deferral, detect out-of-distribution inputs, and show confidence to downstream systems.
5. Set thresholds per context
Different segments deserve different knobs (e.g., new users vs trusted, high-value vs low-risk transactions).
6. Keep a human in the loop where stakes are high
Review queues, second opinions, escalation paths, and auditable rationales.
7. Ship safely
Shadow-mode first, then canary releases with guardrails and rollback. Track both quality and harm metrics.
8. Monitor, learn, adapt
Watch drift, recalibrate, retrain. Capture feedback on mistakes and feed it back into the objective.
The mindset shift
AI isn’t about being right—it’s about being useful when you can’t be certain.
Success is minimizing expected harm while maximizing value.
Progress means getting “less wrong where it matters,” and building systems that fail safely.
In other words, the heart of AI is not prediction; it’s decision-making under uncertainty—with the courage and discipline to price your mistakes and design around them.